

这一切始于周末之初,我想要看看如何让我的新加密算法ChaCha12-BLAKE3在现代CPU上运行得更快。但有一个问题:代码需要既快又安全且可审计,不像大多数加密库中那些成千上万行汇编代码那样。我喜欢我的加密代码是“安全、快速、可审计。三选二”。
尽管过程中遇到了一些波折,但我对在纯Rust中实现ChaCha20/ChaCha12的SIMD加速感到极为惊讶。仅用两天时间就获得了与手工编写汇编代码相差无几的性能,但代码可读、内存安全、可测试、可审计且可更新——这本应是代码合并到代码库前的必要条件,但汇编代码并不具备这些特性。
以下是我所学到的内容。
对于好奇的读者,代码已发布在 GitHub 上:https://github.com/bloom42/chacha12-blake3(位于 chacha12 文件夹中)。
SIMD?
SIMD代表单指令多数据:CPU指令可以操作更大的数据向量。
CPU通常处理最多64位的值,我们称这些为“标量指令”。而SIMD指令允许CPU处理更大的值,对于amd64的AVX-512指令集,最多可达512位。我们称这些为“向量指令”。
以下是一个伪代码示例,我们希望将 4 个 uint64 值相加:
// instead of doing this:
let mut a = [1, 2, 3, 4];
for n in &a {
*n += 10;
}
// do this
let mut vector = u64x4::from_array([1, 2, 3, 4]); // a 256-bit vector of 4 uint64
let x = u64x4::splat(10); // create a 256-bit vector of 4 uint64: (10, 10, 10, 10)
let vector = vector + x;
// vector = u64x4(11, 12, 13, 4);
与生成可能耗时较长的循环相比,向量化代码将编译为大约 3 条指令。
需要注意的一点是,SIMD指令可能比标量指令消耗更多电力(从而产生更多热量),并在某些较旧的英特尔CPU上导致CPU降频(至少在某些情况下),从而对性能产生负面影响。
采用SIMD思维
使用SIMD指令可概括为一个三步流程:
加载 -> 计算 -> 存储
首先,将数据从内存加载到向量寄存器中。
// loads 8 times the int64 with value 1 in a 512-bit vector let v1 = _mm512_set1_epi64(1); // loads the (unaligned) int64 array with 8 elements into a 512-bit vector let v2 = _mm512_loadu_epi64([1, 2, 3, 4, 5, 6, 7, 8]);
然后执行计算操作(加法、异或、减法等)。
// add the 8 64-bit lanes in parallel let v_result = _mm512_add_epi64(v1, v2); // v_result = __m512i(2, 3, 4, 5, 6, 7, 8, 9)
最后将结果存储回内存。
let result = [0i64, 8]; _mm512_storeu_epi64(result.as_mut_ptr(), v_result); // result = [2, 3, 4, 5, 6, 7, 8, 9]
需要注意的是,从内存加载和存储数据的延迟成本相对较高,因此应尽可能减少此类操作。数据最好保存在SIMD寄存器中。
因此,了解目标指令集可用的SIMD寄存器数量至关重要。例如,NEON在arm64架构上提供32个128位寄存器:v0至v31。因此你可以存储多达32个128位向量,从而在无需访问“缓慢”内存的情况下执行操作。
利用SIMD指令加速算法通常有两种方法。
第一种方法是寻找算法中可并行执行的操作,但这取决于具体算法且通常实现起来更为复杂。
第二种方法更通用且易于实现,即把输入数据拆分为多个块,每个块包含 X 个数据块,其中 X 是可用通道数,这样就可以并行计算 X 个数据块。
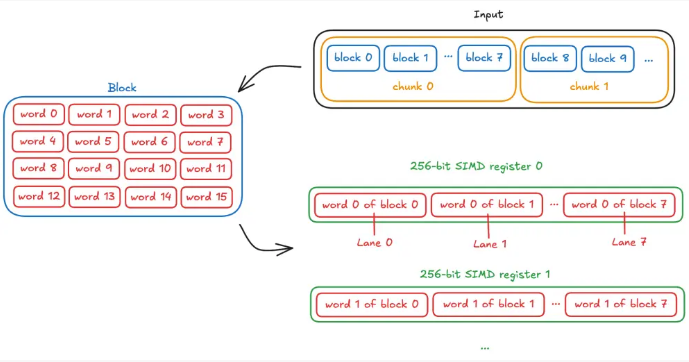
以ChaCha20为例,它处理32位(4字节)的字,这些字组成512位(64字节)的块(16 × 32位 = 512位 = 64字节)。
因此,如果我们有 256 位向量可用,我们将并行处理 8 个块(通道)(256 / 32 = 8),因此我们的输入数据块长度为 8 个块,对于 8 × 64 = 512 字节或更大的输入,可达到单核全速。
另一个例子是BLAKE3,它也对32位字进行操作。BLAKE3在支持AVX-512指令的机器上,对于16KiB或更大的输入,可达到单核全速运行:它将输入数据分割为16个块(称为分块),每个块为1024字节,并使用AVX-512指令并行处理这16个块,每次操作计算16个32位状态字。在支持 AVX2(256 位向量)的机器上,当输入大小为 8KiB 或更大时,它可达到单核全速运行,因为 256 位向量中仅提供 8 个 32 位通道。
明确目标
实现 SIMD 加速代码需要时间并增加维护负担,因此您应明确代码的运行环境以集中精力优化。
如果你的代码仅在高端 Intel/AMD 服务器上运行,那么专注于 AVX-512 可能就足够了。
另一方面,如果你的代码主要在消费级机器上运行,那么专注于 AVX2 和 NEON 可能是最佳选择。
此外,如今实现 SSE2 SIMD 毫无意义,因为自 2015 年以来生产的绝大多数处理器都支持 AVX2。
在我的情况下,密码学无处不在。例如,ChaCha被Go和Rust的随机数生成器所使用。因此,我决定实现AVX2、AVX-512、NEON和WASM simd128加速。
我能够实现这一点,因为ChaCha专门设计为能够适应不同SIMD指令集,因此将ChaCha从AVX2迁移到AVX-512,例如,仅仅需要修改一个变量的值和几个内置函数的名称。
CPU特性检测
SIMD加速代码依赖于其运行的CPU上是否支持相应的指令集。
在Rust中实现CPU特性检测有几种不同的方法。
第一种是通过运行时检测,使用std::arch模块提供的宏:
fn foo() {
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
{
if is_x86_feature_detected!("avx2") {
return unsafe { foo_avx2() };
}
}
// fallback implementation without using AVX2
}
此方法需要标准库,而在低级代码开发中标准库可能不可用。
第二种方法是使用编译时特性检测:
#[cfg(all(target_arch = “x86_64”, target_feature = “avx512f”))]
还有一些更复杂的方法,但我不推荐使用,因为它们会让包的用户感到困惑,尤其当你的包是某个包的依赖项的依赖项的依赖项时。
由于运行时检测依赖于标准库,而标准库在某些项目(如嵌入式软件)中可能不可用,因此我建议默认提供运行时检测,并通过 Cargo 特性让包的用户选择仅在构建时进行特性检测,以便他们能精确指定代码将运行的 CPU 类型。
例如:
Cargo.toml
[features]
default = ["std"]
# enables the use of the standard library for CPU features detection on supported platforms
std = []
fn my_function() {
// use runtime detection
#[cfg(feature = "std")]
{
#[cfg(target_arch = "x86_64")]
if is_x86_feature_detected!("avx512f") {
return my_function_avx512();
}
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
if is_x86_feature_detected!("avx2") {
return my_function_avx2();
}
}
// use compile-time detection
#[cfg(not(feature = "std"))]
{
#[cfg(all(target_arch = "x86_64", target_feature = "avx512f"))]
return my_function_avx512();
#[cfg(all(any(target_arch = "x86", target_arch = "x86_64"), target_feature = "avx2"))]
return my_function_avx512()
}
// pure-software fallback
return my_function_software();
}
选择您的纯 Rust SIMD 实现
在纯 Rust 中使用 SIMD 指令有几种不同的方式。
标准库中的实验性 simd 模块。不幸的是,它目前仅在 Rust 夜间版本中可用。我们将在本文后面介绍这个模块。
wide crate,这是一个第三方 crate,复制了稳定版 Rust 的 simd 模块,但目前仅限于 256 位向量。我无法使用它,因为它拉取了太多的依赖项。
use wide::*;
fn main() {
let a = u32x4::splat(1);
let b = u32x4::from([1, 2, 3, 4]);
let result = a + b;
assert_eq!(result.to_array(), [2, 3, 4, 5]);
}
如果你不介意额外的依赖项,我推荐使用以下方法。
pulp crate 是 SIMD 的高级抽象,如果你愿意,可以将其视为 SIMD 的 rayon。与 wide 类似,我无法使用它,因为它依赖太多库。我也不太喜欢运行时检测 SIMD 指令,因为目前它无法用于 no_std 目标。
use pulp::Arch;
fn main() {
let mut v = (0..1000).map(|i| i as f64).collect::<Vec<_>>();
let arch = Arch::new();
arch.dispatch(|| {
for x in &mut v {
*x *= 2.0;
}
});
for (i, x) in v.into_iter().enumerate() {
assert_eq!(x, 2.0 * i as f64);
}
}
最后,还有Rust标准库中的arch模块。
arch的子模块:x86、x86_64、aarch64… 暴露每个平台可用的原始内置函数(例如 _mm512_add_epi32)和向量寄存器(例如 __m512i)。
这是最低级别的实现,会导致更多重复代码,但它是目前唯一无需依赖稳定版 Rust 即可工作的方案。因此我选择了它作为我的实现方案。
自动向量化
我想讨论一个重要点:LLVM 执行的自动向量化。
例如,尽管尝试过几次,但要实现比基本点积操作更快的两种缓冲区异或(XOR)方法非常困难:
input_block .iter_mut() .zip(keystream) .for_each(|(plaintext, keystream)| *plaintext ^= *keystream);
事实上,编译器识别此模式,并根据可用指令集自动生成向量化实现。
编译器拥有的信息越多(例如块/区块的大小等),它就能进行更多的优化,如自动向量化。一如既往,Rust 的智能编译器 和 LLVM 都在这里为我们保驾护航,让我们的生活更轻松。
我的建议是,除非你有确凿的证据证明这是瓶颈,否则不要费心为常见操作(如对两个缓冲区进行异或运算/加法等)手动实现SIMD优化。编译器很可能会自动为你进行向量化。
测试
别忘了用不同 SIMD 指令集的实现进行测试。
你可以使用 RUSTFLAGS 环境变量来选择性禁用 CPU 功能:
# run tests for generic (no SIMD acceleration) code RUSTFLAGS="-C target-cpu=native -C target-feature=-avx2,-avx512f" make test # run tests for AVX2 code RUSTFLAGS="-C target-cpu=native -C target-feature=-avx512f" make test # run tests for AVX-512 code make test
可移植的SIMD(希望)即将到来
可移植的SIMD(Rust的simd模块)可能是Rust目前在夜间版本中提供的最令人兴奋的功能之一。
它将大大减轻开发人员维护快速、高效且易于维护的代码的负担。
它将使我们能够仅需一次实现算法,即可支持所有向量大小,使用高级代码如 u32x8 操作一个由 8 个 32 位通道组成的 256 位向量,然后 Rust 编译器将在编译时为不同 CPU 架构选择具体指令,并自动回退到纯软件实现。
该代码与 wide 类似,但不依赖任何第三方库,并支持长度达 512 位的向量(而 wide 仅支持 256 位)。
fn main() {
let a = u32x4::splat(1);
let b = u32x4::from([1, 2, 3, 4]);
let result = a + b;
assert_eq!(result.to_array(), [2, 3, 4, 5]);
}
这真是令人惊叹,首先是因为我们无需再费心去学习每个不同平台/向量大小的内置函数的具体名称。
其次,这将极大简化我们的代码。例如,我曾两次实现ChaCha20算法,分别针对128位向量。一次是针对NEON(arm64),另一次是针对wasm32的simd128。虽然代码几乎相同,只需更改类型和内置函数的名称,但这意味着需要测试、维护和文档化的代码量会增加。
借助可移植SIMD,我只需基于u32x4类型(即包含4个32位通道的128位向量)进行实现,Rust会将其编译为针对任何支持128位向量指令平台的优化代码(如arm64上的NEON、x86上的SSE2、wasm32上的simd128等)。
这也将极大简化SIMD代码的测试,因为使用u32x4的跨平台实现可在任何支持128位向量的平台上测试,而std::arch模块则需要特定硬件才能运行测试。
我真的迫不及待想看到这个功能在Rust稳定版中实现!
结语
你使用Rust的时间越长,就越能理解为什么它最终会席卷整个计算堆栈,从微控制器到大型服务器,涵盖WebAssembly、机器人、卫星以及其间的一切。
如前文文章所述,加密库中超过37%的漏洞是内存安全问题,因此很明显,汇编语言在加密代码中的应用正逐渐淘汰,而加密代码是数字时代最基础的部分之一,Rust是唯一合理的替代方案。


